PyTorch’s Autograd feature is what makes PyTorch flexible and fast for building machine learning projects. It allows for the rapid computation of multiple partial derivatives (gradients) over a complex computation.
Differentiation in Autograd
When making a PyTorch Tensors if you use the parameter requires_grad=True it signals to autograd that every operation must be tracked
We create a tensor Q from a and b
import torch
a = torch.tensor([2., 3.], requires_grad=True)
b = torch.tensor([6., 4.], requires_grad=True)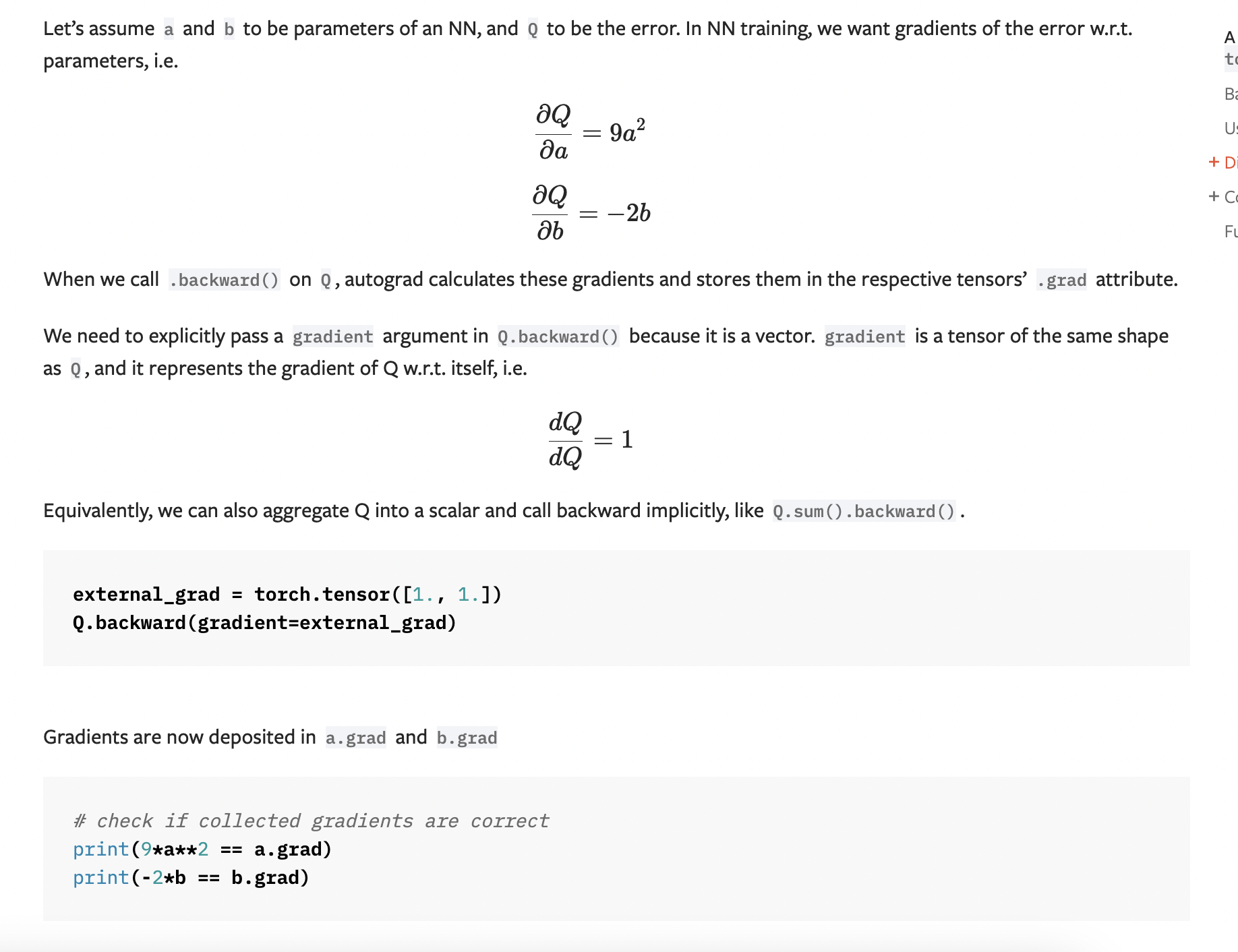
Computational Graph
Autograd keeps a record of data (tensors) & all executed operations (along with resulting new tensors) in a directed acyclic graph (DAG)
In a DAG the leaves are the input tensors and the roots are the output sensors. By tracing this graph you can automatically compute the gradients using the chain rule
Forward Pass:
- Run the requested operation to compute a resulting tensor
- Maintain the operation’s gradient function in DAG
Backward Pass kicks off when .backward() is called on the DAG root. Autograd:
- computes gradients from each
.grad_fn - Accumulates them in the respective tensor’s .grad attribute
- Using chain rule propagates all the way to leaf tensors
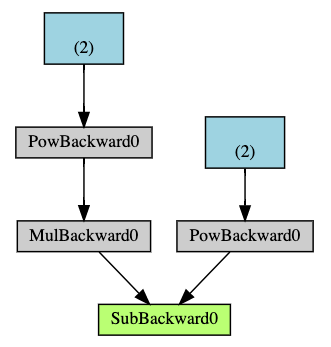
- Arrows - Direction of forward pass
- Nodes - Backward function of each operation in forward pass
- Leaf nodes (blue) - represent leaf tensors
aandb