Blog link: https://www.pi.website/research/real_time_chunking
Problem with VLAs are that they’re slow to inference, and this could mean that robot takes non-optimal actions and mess up a real world task (eg. spill coffee in your lap)
For VLAs you need a system that lets the model think about it’s future actions while executing a previous one. Action Chunking (inferencing 50 actions for every 1 inference call) is a good starting point but when you generate new chunks old chunks might not “agree” with the new ones
Model generates 50 chunks in one call, and it takes 3 chunks of time to generate 50 more chunks
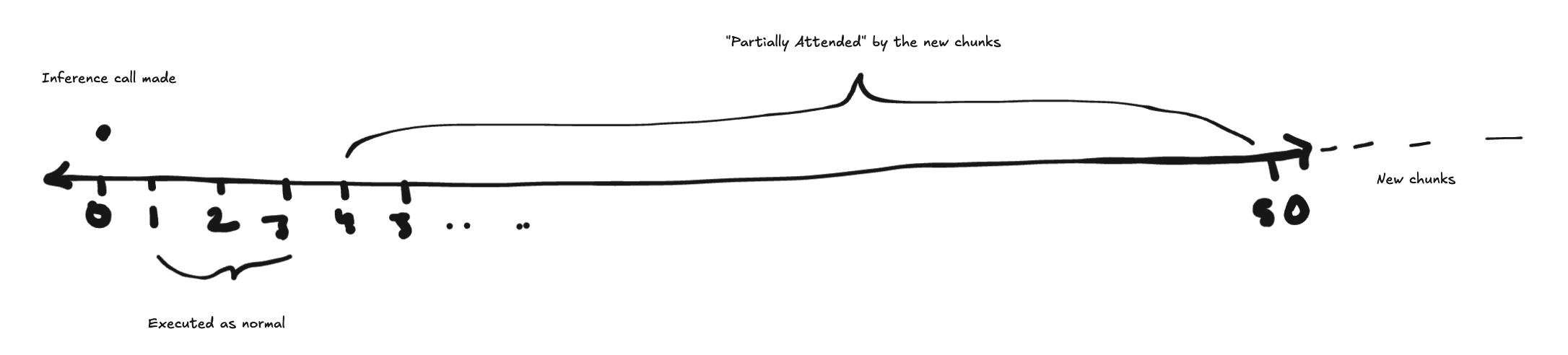
W Drawing
RTC is faster since it eliminates inference pauses between chunks, the blog also hypothesizes that RTC would help with precision since the pauses a dynamic robot made to inference was not account for by the model