DDP is PyTorch’s mechanism for data-parallel training across multiple processes
Every process holds a full copy of the model but each one trains on a different slice of the data
Challenge is to keep the model replicas perfectly in sync without having to manage the communication manually
DDP Lifecycle
Construction: When you wrap your model in DDP two things happen:
- Model’s
state_dictbroadcast from rank 0 to ever other process (guaranteeing all replicas begin from exact same state) - Each process builds a local
Reducer, object responsible for gradient synchronization
Forward Pass: Normal local model running on local data
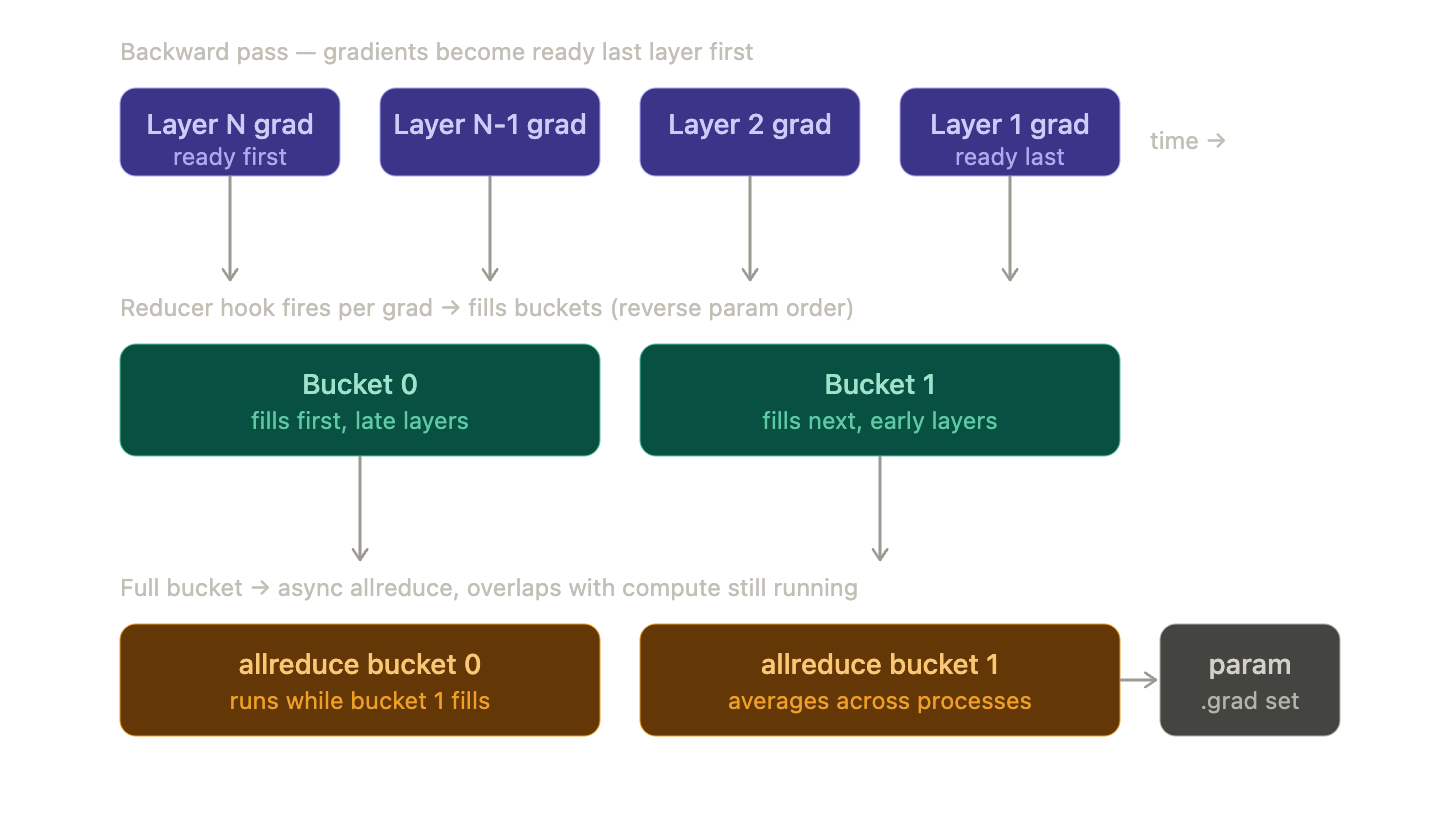
Backward Pass: Calling .backward() on your loss, as autograd computes each gradient the corresponding hook fires and marks that parameter’s gradient “ready”
Once all the gradients in a group are ready DDP launches an asynchronous allreduce to average them across processes; eg. waits for all bucket 0 to be ready then runs allreduce across all the gpus synchronizing the gradients and goes on for all of the buckets
When everything finishes the averaged gradients are written into parameter’s .grad field, so after backward every process has identical gradients
Ayush Note: At first I thought that averaging gradients makes you “lose” progress; this isn’t the case, averaging gradients gives you a better gradient with lower variance. The lower variance gradient means you have to take less steps to reach convergence
Optimizer step: Normal optimizer step, nothing crazy happens
Optimization
Most important implementation detail is gradient bucketing
Instead of firing off a separate allreduce for every parameter, the Reducer groups parameter gradients into buckets and reduces one bucket at a time