Paper Link: https://arxiv.org/pdf/2501.09747
FAST’s goal is to train policies
Time Series Compression
Key takeaway: Any sufficiently effective compression approach when applied to the action targets is suited to improve the training speed of VLA models
In the paper they use DCT, purpose of this algorithm is to transform continuous signal into a sum of cosine elements of various frequencies
Low frequencies capture shape, high frequency reflect sharp jumps
Compared to learn compression approaches DCT compression is analytical approach thus simple and fast
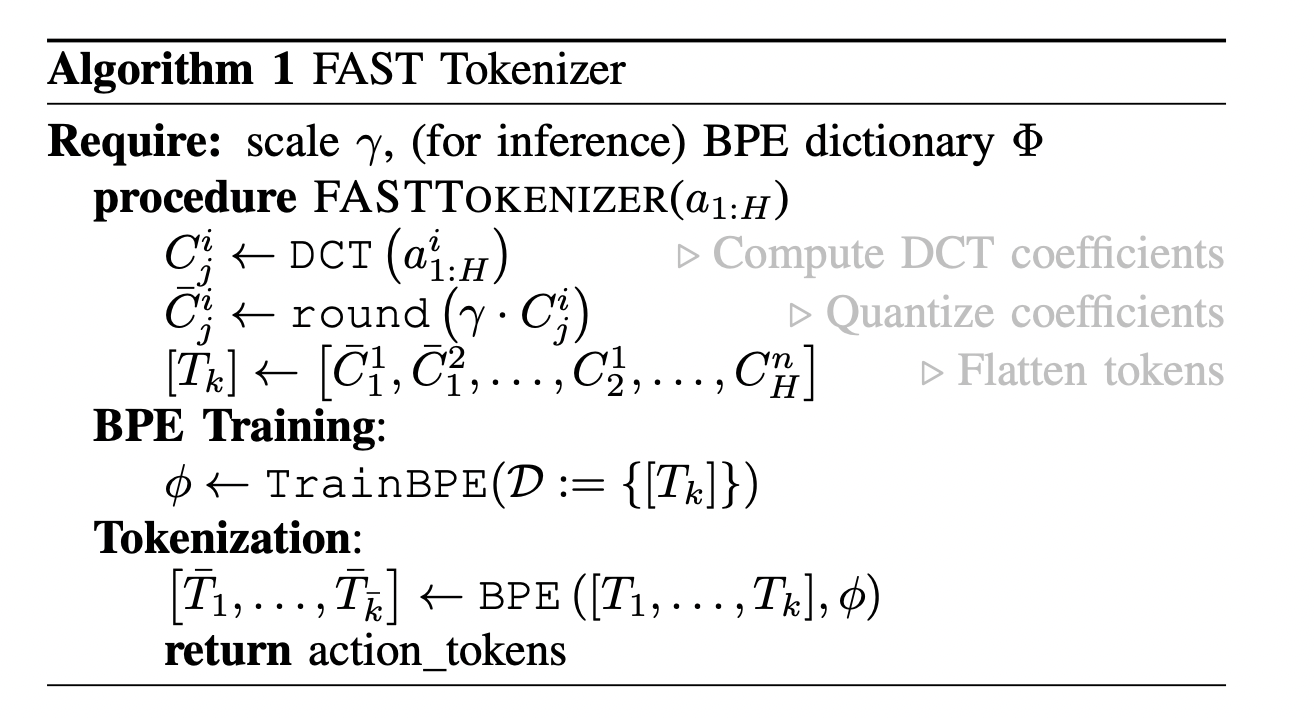
FAST Tokenization Algorithm
- Normalize the input actions, s.t 1st and 99th quantile of values in the training dataset for each action maps to range
- Purpose of this is to make tokenization of cross-embodied datasets with different action scales easier
- Apply DCT to each action dimension separately
- To compress DCT converted signal we simply omit insignificant coefficients, implemented using scale-and-round operation, scaling coefficient is a hyperparam
- Scale and Round = take a real number/constant x, scale it by a constant s, then round to nearest integer
- Flatten the matrix into 1-D vector of integers
- Use BPE to merge tokens, making action dense tokens
Note: Order of flattening DCT coefficient matrix prior to BPE can have a significant impact, the paper goes with column first flattening
The tokenizer only has 2 hyperparameters, scale applied to DCT coefficients before rounding and vocab size of BPE compression step. Paper uses rounding scale 10 and BPE vocab size 1024
DCT based tokenization has shown to be much better and a lot less tedious to train compared to Vector Quantization
Universal Robot Action Tokenizer
The only learned part of the tokenizer is the vocabulary of BPE encoder, which needs to be trained for each new dataset the tokenizer is being applied to
The learning process is usually fast (only a few minutes), since it adds friction Physical Intelligence aims to train a universal action tokenizer that can encode chunks of robot actions from any robot
For best results, normalize input action range
Inference Speeds: