Llama 4’s release blog: https://ai.meta.com/blog/llama-4-multimodal-intelligence/
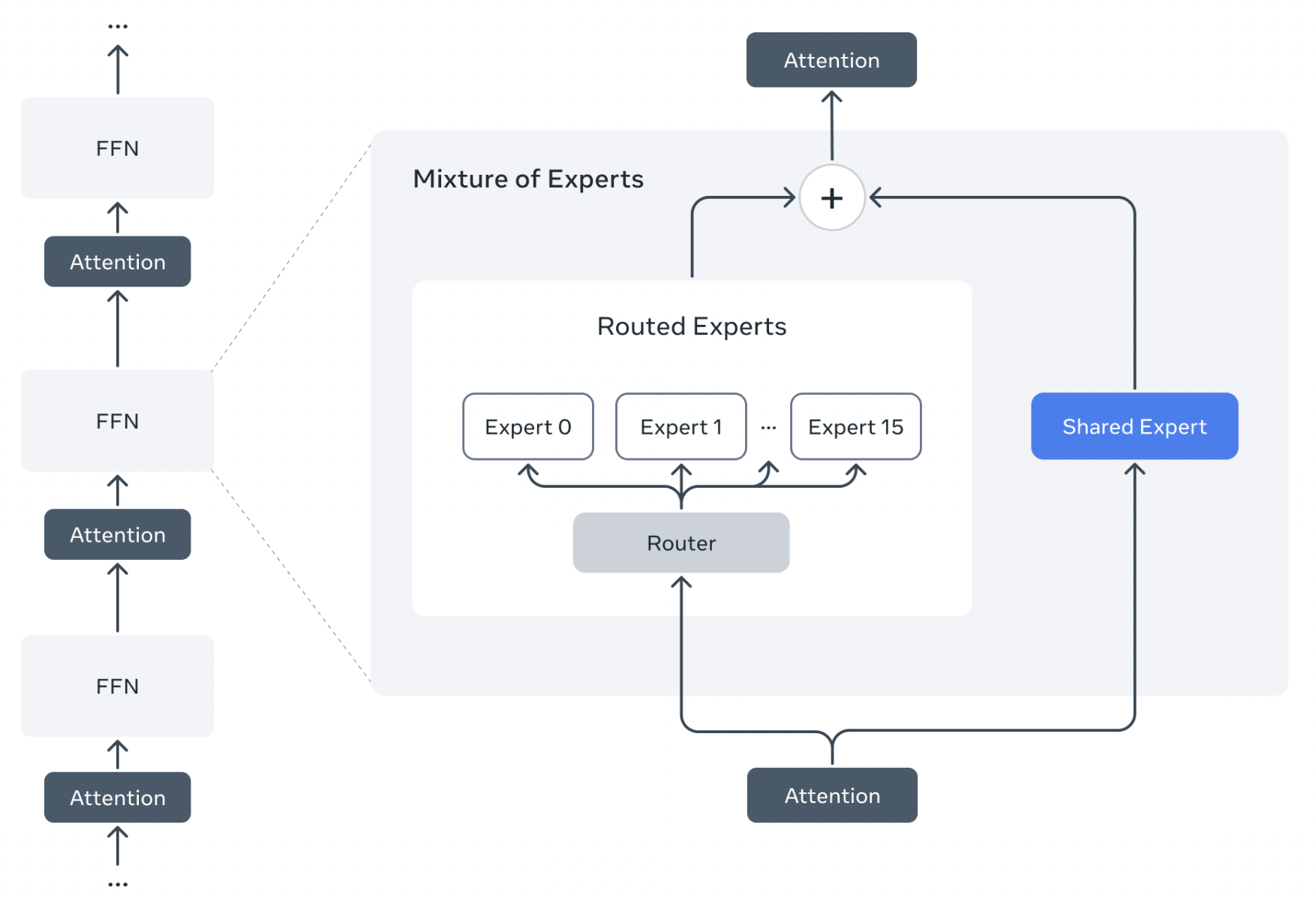
Mixture of Experts
The new Llama 4 Models are the first Llama models to use a Mixture of Experts technique
To learn more about this architecture (not Llama 4 specific) checkout Mixture of Experts
Llama 4 Specifications:
- Each MoE Layer uses 128 router experts and a shared expert
Each token is sent to a shared expert and one of the 128 routed experts
While all the parameters are stored in memory only a subset of the total parameters are activated, improving inference efficiency by lowering model serving costs and latency
Early Fusion
Llama 4 implements this thing called Early Fusion
MetaP
MetaP is a training technique which sets hyper-parameters for each layer. Eg. learning rates and initialization scales.