Mixture of Experts (MoE) is a technique that uses different sub-models (“experts”) to improve the quality of LLMs
Excellent Video: https://youtu.be/sOPDGQjFcuM?si=_QAwMjZH3GSsU9Yk
Architecture
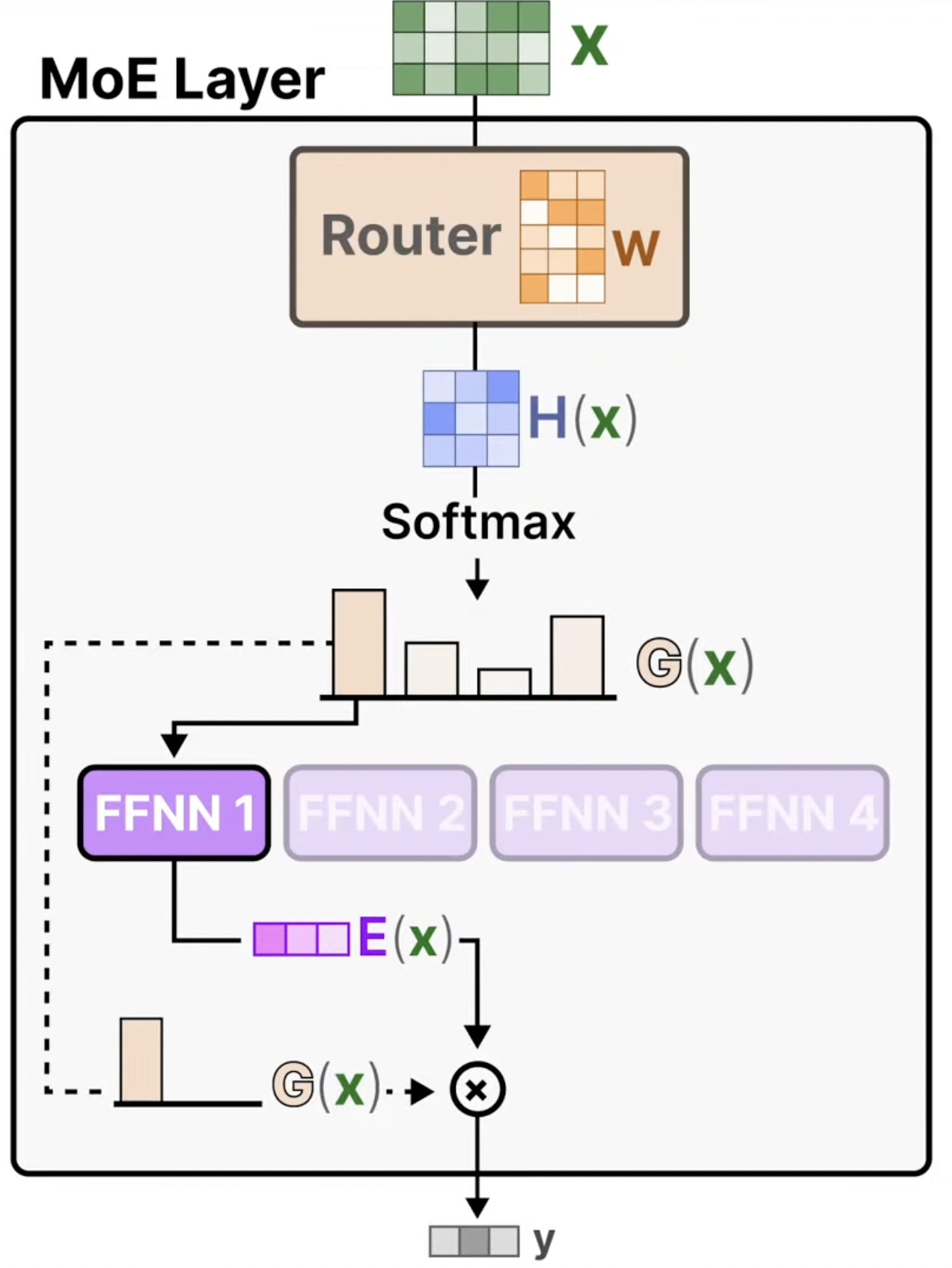
Experts - These “experts” are Neural Networks and at least one can be activated
Router - Determines which tokens are sent to which experts
Expert?
An expert is not specialized in a specific domain but rather it learns syntactic information on a token level instead (eg. punctuation, verbs, conjunctions)
A given text will pass through multiple experts before the output is generated and even the addition of one token can result in a different expert “route taken”
Eg: There’s 3 experts labeled A, B, and C
A -> B -> A -> C
But with the addition of a token the path may change to
B -> C -> A -> B
Expert Capacity
To prevent certain experts being overtrained and others being undertrained we can limit how many tokens they can process, called the expert capacity.
By setting an expert’s expert capacity to 3 it can only process 3 tokens. Tokens which exceed this threshold are sent to the next most probable expert, if all experts are capacity any new token will not be processed by any expert but sent to the next layer (token overflow)
Router?
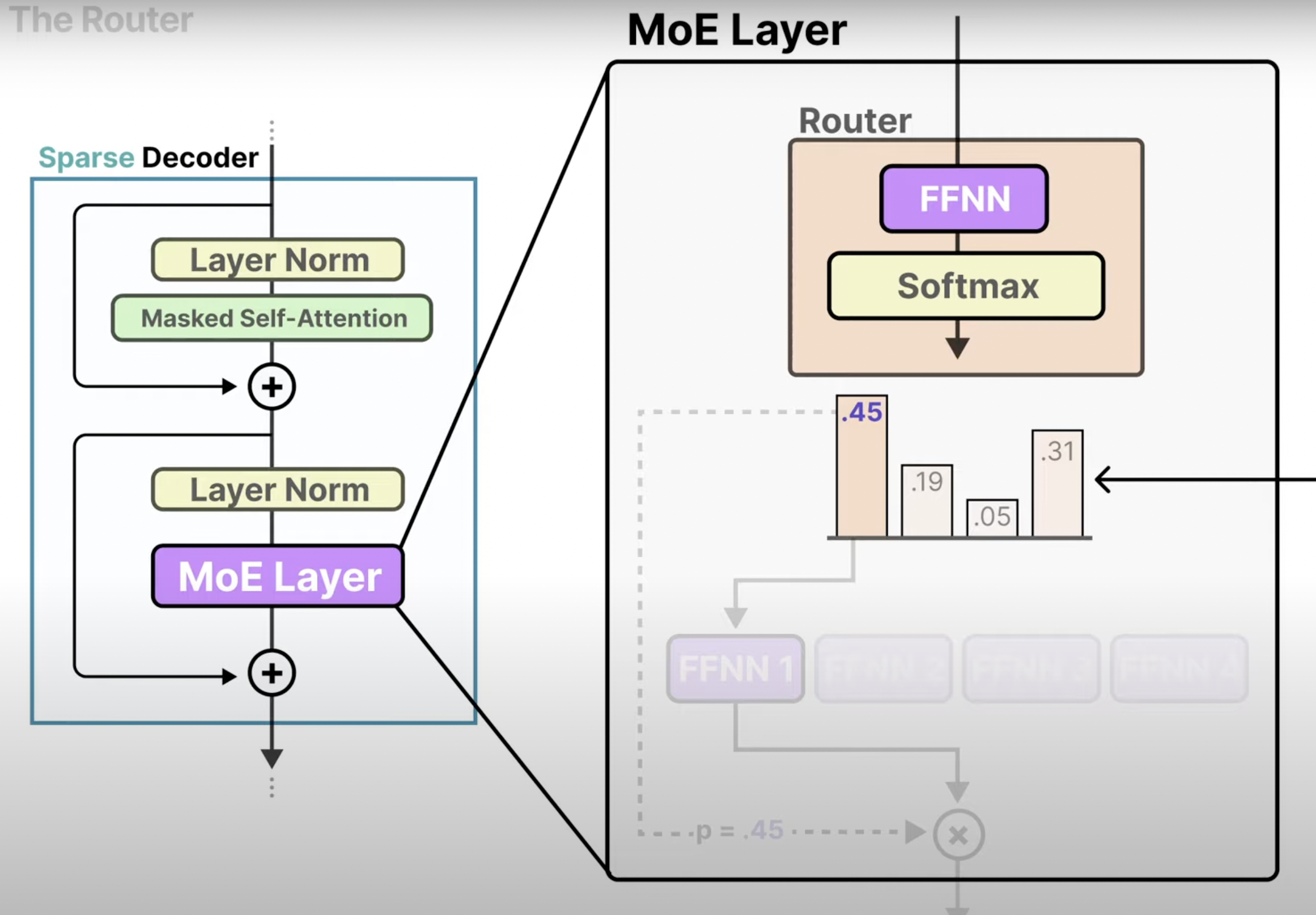
A Neural Network is used to select and activate the best expert for each task
It’s put through a softmax to get probability distribution to pick the best expert
Load Balancing
During training some experts may learn faster and more than other experts
Some set of experts may be chosen to frequently regardless of the input
KeepTopK
There’s a method called KeepTopK where we introduce trainable (gaussian) noise which helps us prevent the same expert(s) from always being chosen
Output of Router = Input * Router Weights + Gaussian Noise
By introducing noise some experts may get lower scores giving more opportunities for other experts to train
Token Choice
Routing tokens to a few selected experts, it allows for a given token to be sent to one expert (top-1 routing)
or to more than one expert (top-k routing), k = # of experts selected
Auxiliary Loss
Auxiliary Loss is updated during training to lower the CV as much as possible resulting in creating more equal importance among the experts
Coefficient Variation (CV) =
High Coefficient Variation = Lots of differences in the standard deviation
Low Coefficient Variation = Similar importance scores