Paper Link: https://research.nvidia.com/labs/lpr/locate-anything/LocateAnything.pdf
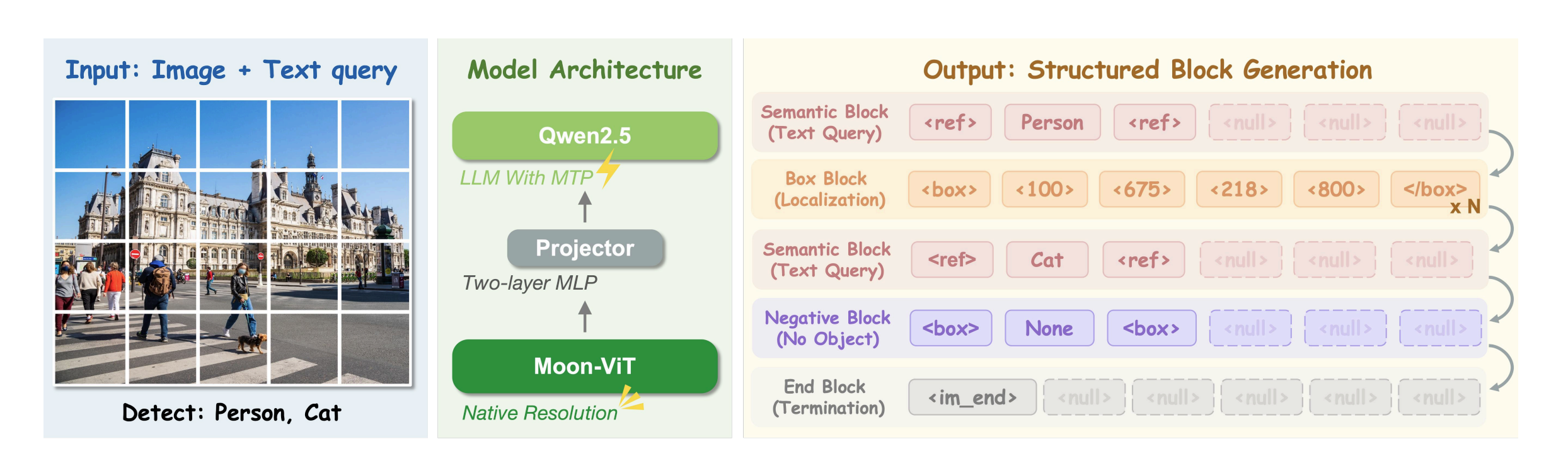
LocateAnything is a generative vision-language model for localization
This paper’s main contributions are:
- Early exploration of applying multi-token prediction to VLM-based detection/grounding via Parallel Box Decoding
- Hybrid decoding policy that detects unreliable parallel blocks and performs localized NTP re-decoding only for the problematic block