Paper Link: https://arxiv.org/pdf/1710.03740
Training deep neural networks using half-precision floating point numbers halves memory requirements and speeds up arithmetic
The paper introduces 3 techniques to prevent model accuracy loss: maintaining a master copy of weights in FP32, loss-scaling that minimizes gradient values becoming zeros, and FP16 arithmetic with accumulation in FP32
FP32 Master Copy of Weights
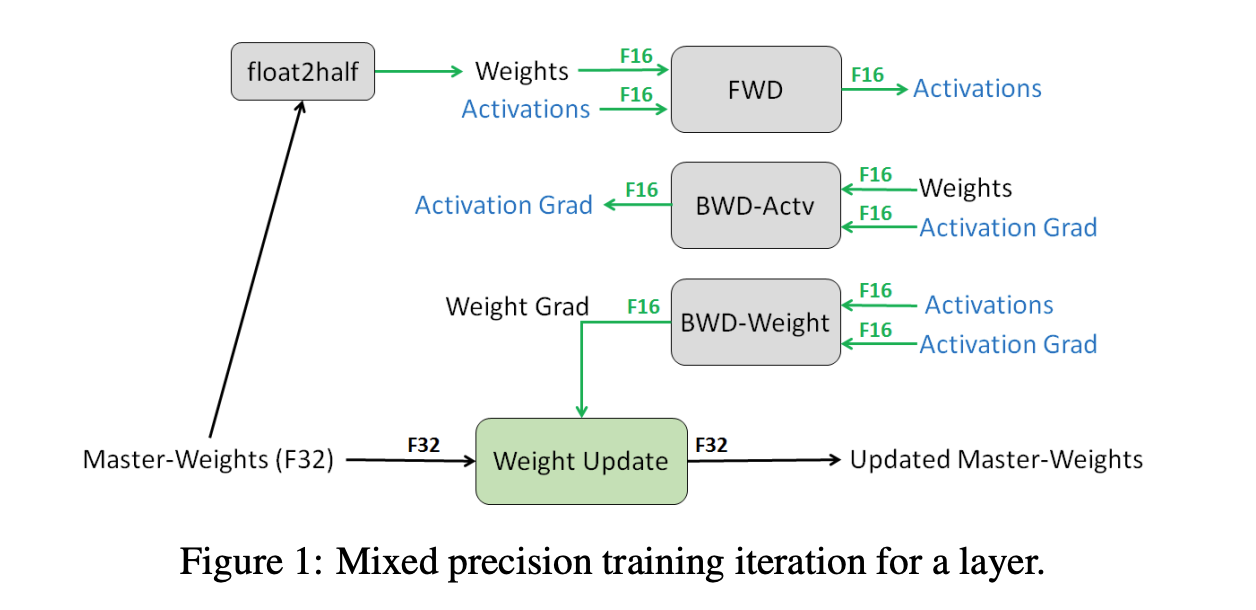
There are two possible reasons why a number of networks require FP32 Master Weights:
- Updates become too small to be represented in FP16
- Ratio of weight value to weight update is very large
Loss Scaling
A FP16 number spends 5 bits on the exponent
During training gradient magnitudes are tiny (much smaller than 1) so their exponents are almost all negative
Entire upper half of FP16’s range sits empty; Gradients are never that large
Big chunk of gradients are smaller than the smallest number FP16 can hold (so they get rounded to 0 and disappear)
Solution: scale the gradients up, multiply every gradient by a constant
Multiplying by 8 (
Small values that were falling off the bottom edge now land inside the representable range instead of becoming zero, and since the upper range wasn’t being utilized the shift is “free”
Arithmetic Precision
To maintain model accuracy some networks require that FP16 vector dot-product accumulates the partial products into an FP32 value which is converted to FP16 before writing to memory