During Reinforcement Learning training we want to learn a policy that maximizes expected return.
Policy gradient methods do this by estimating the gradient of the RL objective with respect to the policy parameters, then using Gradient Ascent to improve the policy.
Objective
A policy
A trajectory is a sequence of states, actions, and rewards:
The RL objective is to maximize expected return:
where
Policy gradient methods solve this with Gradient Ascent:
Many RL optimizers used for LLM post-training, such as PPO and GRPO, are policy gradient algorithms. They operate by:
- estimating the policy gradient
- performing gradient ascent using that estimate
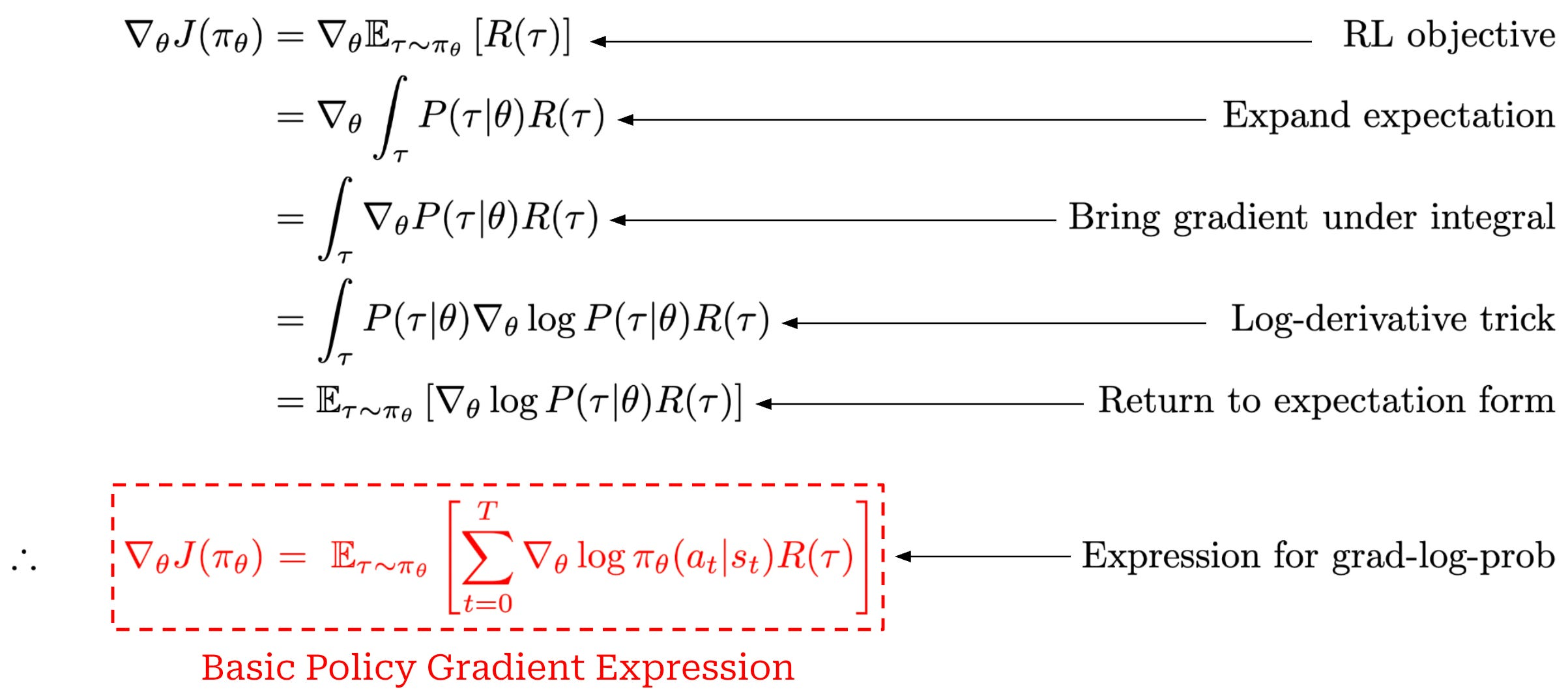
REINFORCE estimator
The basic policy gradient estimator is:
This means:
- if an action is part of a high-return trajectory, increase its probability
- if an action is part of a low-return trajectory, decrease its probability
The
This lets us estimate the gradient from sampled trajectories, even though the environment dynamics may be unknown or non-differentiable.
Reward-to-go
A problem with using the full trajectory return
Reward-to-go replaces the full trajectory return with the sum of rewards observed after an action:
where
Using reward-to-go gives:
This reduces variance by only assigning credit to actions for rewards that could have happened because of those actions.
Baselines
To further reduce variance, we can subtract a baseline from the return:
The baseline does not bias the gradient as long as it does not depend on the sampled action
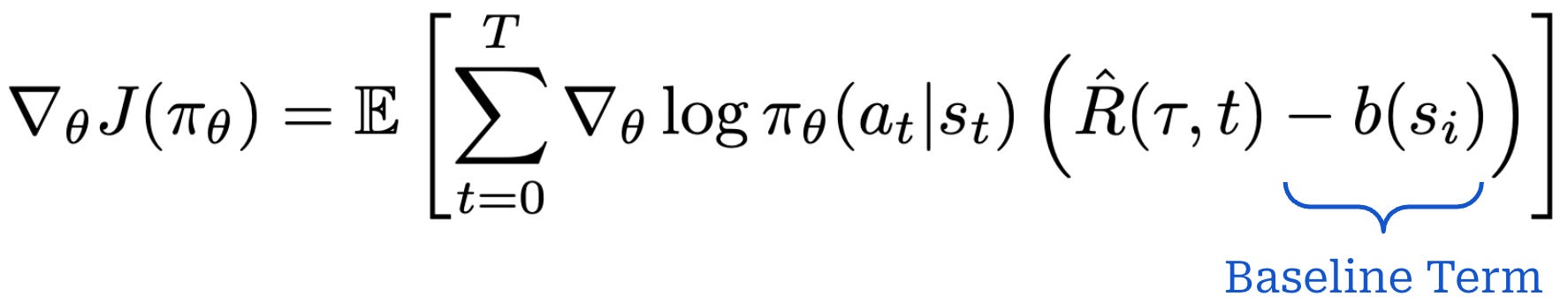
A common problem with vanilla policy gradient algorithms is the high variance in gradient updates… In order to alleviate this, various techniques are used to normalize the value estimation, called baselines. Baselines accomplish this in multiple ways, effectively normalizing by the value of the state relative to the downstream action (e.g. in the case of Advantage, which is the difference between the Q value and the value). The simplest baselines are averages over the batch of rewards or a moving average.
Value functions and advantage
The most common baseline is the value function:
The action-value function estimates the expected return after taking action
The advantage function compares an action to the average action from that state:
Intuitively:
- positive advantage means the action was better than expected
- negative advantage means the action was worse than expected
Policy gradient methods often use an estimated advantage:
This is the form used by many actor-critic methods.
Generic Policy Gradient
Options for computing the policy gradient were summarized with a more generic policy gradient expression

On-policy sampling
Vanilla policy gradient is usually on-policy: the trajectories used to estimate the gradient are sampled from the current policy. If the policy changes too much, old samples may no longer represent the current policy well.
This is one reason algorithms like PPO limit the size of policy updates.
Summary
Policy gradient methods directly optimize the policy by increasing the probability of actions that lead to better-than-expected outcomes and decreasing the probability of actions that lead to worse-than-expected outcomes.
The main progression is:
- full trajectory return: simple but high variance
- reward-to-go: credits actions only for future rewards
- baselines: reduce variance without changing the expected gradient
- advantage estimates: compare actions against what was expected from the state
- PPO / GRPO: stabilize policy-gradient updates for practical training