SAM 3.1 Blog: https://ai.meta.com/blog/segment-anything-model-3/
SAM 3 is a unified model for detection, segmentation, and tracking of objects in image and video using text, exemplar, and visual prompts across
Linking language to specific visual elements in images or videos is a major challenge in computer vision. Traditional models focus on object segmentation with a fixed set of text labels (eg. can process “person” but struggles with “striped red umbrella”)
SAM 3 accepts text prompts, open-vocab short noun phrases, and image exemplar prompts which eliminates constraints of fixed label sets
SAM 3 supports variety of prompt modalities (concept prompts such as simple noun phrases and image exemplars, as well as visual prompts, such as masks, boxes, and points)
SAM 3 delivers a 2x gain over existing systems in both image and video
Data Challenge
Getting high-quality annotated images with segmentation masks and text labels across a range of categories and visual domains is a significant challenge, this type of data doesn’t exist at scale on the web
Using human annotators to mask every occurrence of an object category is time-intensive and complex task
They address this by developing a data engine that leverages SAM 3, human annotators, and AI models which allows speed-ups in annotation 5x faster on negative prompts (concepts not present in image/video) and 36% faster for positive prompts
This allowed them to create a dataset with over 4 million unique concepts
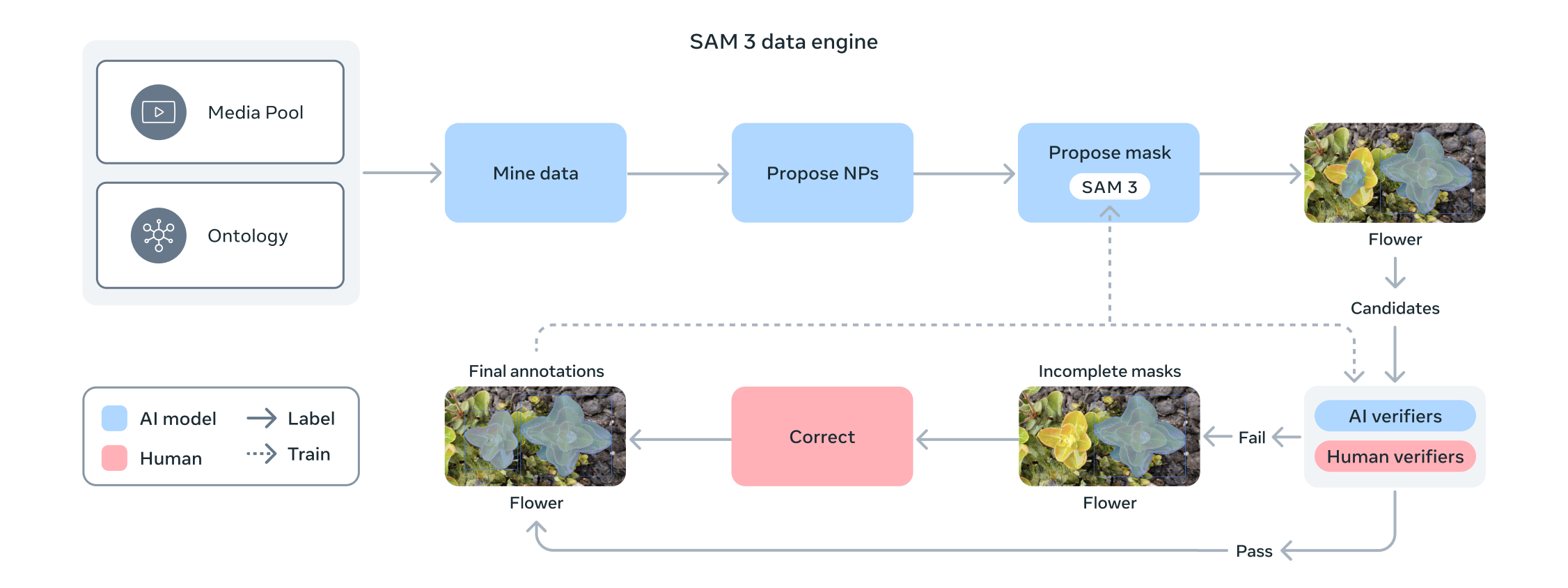
Human and AI annotators verify and correct proposals, resulting in a feedback loop that scales dataset coverage
Delegating human annotation tasks to AI annotators they double the throughput compared to a human-only annotation pipeline. Annotators also automatically filter out easy examples, focusing valuable human annotation effort on most challenging cases where SAM 3 fails
Model Architecture
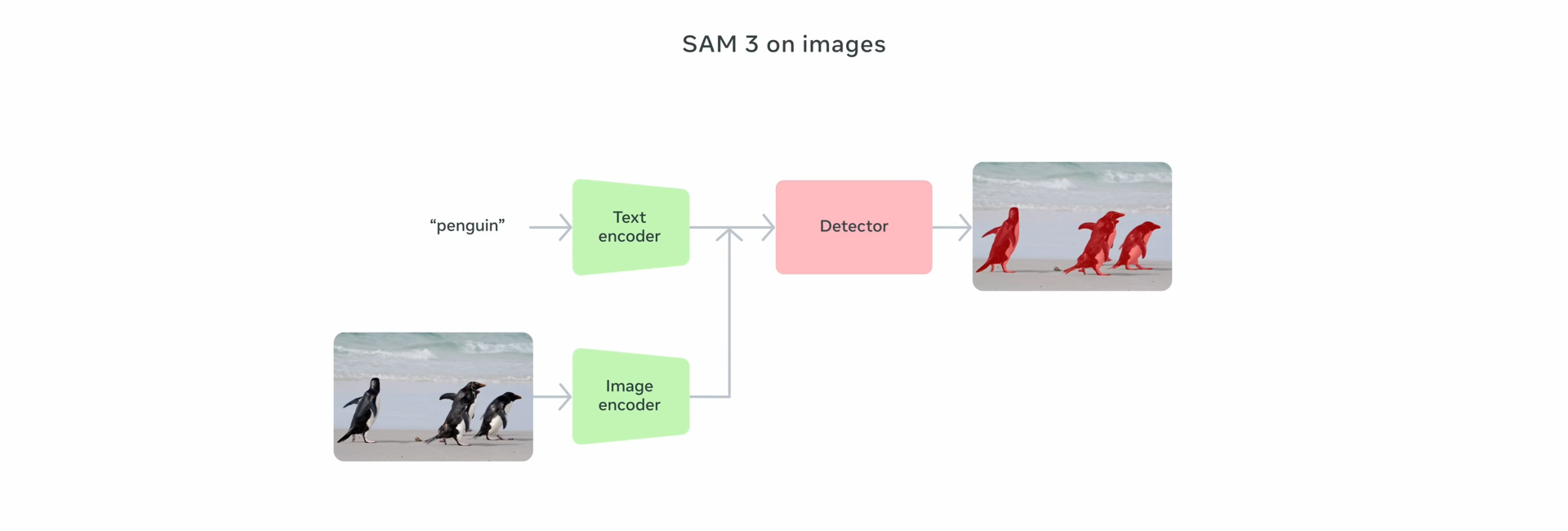
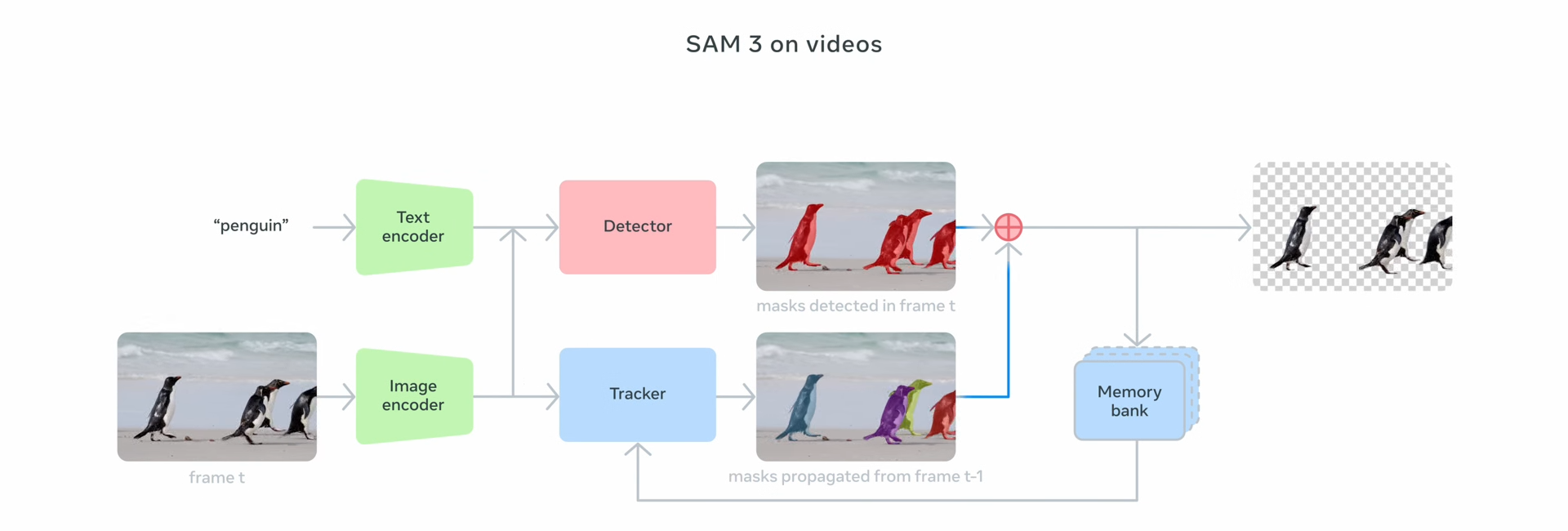
The text and image encoders in SAM 3 is from Meta Perception Encoder
The detector component is based on the DETR model which first to use transformers for object detection
Memory bank and memory encoder used in SAM 2 is the basis for the Tracker component