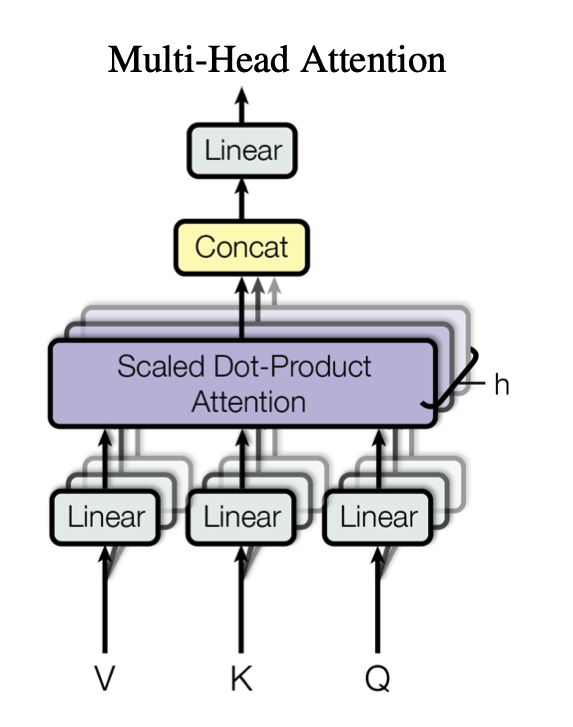
MultiHead(Q, K, V) = Concat(head
This builds on top of Scaled Dot-Product Attention
Multi-head attention extends the basic attention mechanism by allowing the model to attend to different parts of the input from multiple perspectives simultaneously
The input for multi-head attention is linearly transformed to be smaller
Design