Paper Link: https://arxiv.org/abs/2412.16346
SOUS VIDE (Scene Optimized Understanding via Synthesized Visual Intertial Data from Experts) is a behavior cloning pipeline that produces drone navigation policy capable of zero-shot sim2real transfer, entirely in simulation
Flying in Gaussian Splats (FiGS)
In this paper they generate GSplats from short video recordings (2-3 mins), they walk-through with handheld camera and from the video they extract a set of training images and use the open-source tool Nerfstudio to train the GSplat model
The resulting model can generate a photorealistic image from a virtual camera at any pose covered by the training images given a camera pose (p, q) where p represents position and q the orientation in quaternion form
Drone Dynamics Model
Drone state:
- Where it is:
- How fast it’s moving:
- Which way it is tilted / rotated: orientation q
Controls:
- How hard it pushes upward: thrust
- How fast it rotates around its 3 axes:
They mention three frames:
- World frame (W): fixed coordinates for the environment
- Body frame (B): coordinates attached to the drone
- Camera frame (C): coordinates attached to the camera
State Vector:
horizontal position in x horizontal position in y height
Control Input:
Normalized thrust command Desired angular velocity around the drone’s body axes
Generate Training Data
Flow:
- Pick random drone and random starting condition
- Let an expert controller drive it toward the desired trajectory
- Record states, actions, and images
- Repeat many times
They have a desired trajectory the drone should follow:
desired states overtime desired controls over time
Then they generate many slightly different practice runs around the desired trajectory by randomizing:
- drone’s physical parameters
- the starting state
Architecture
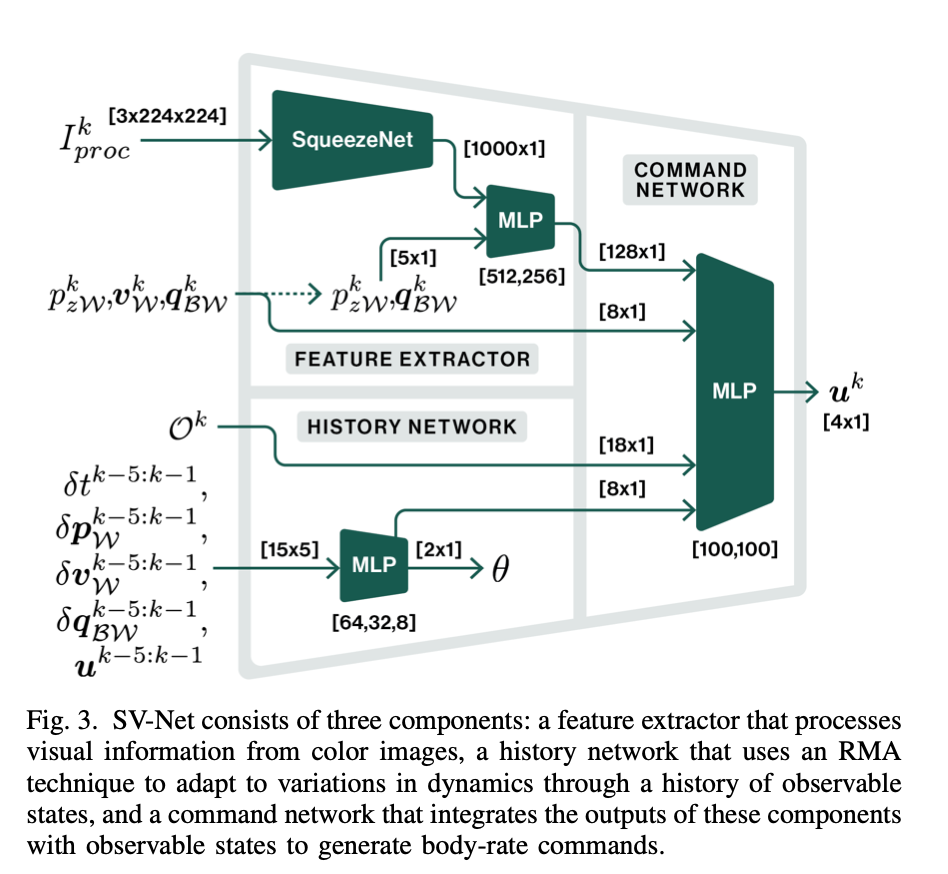
SqueezeNet is a CNN who’s job is to compress the image into useful visual features, it takes in 3 color channels 224 by 224 pixels
It outputs [1000 x 1]
Concatenate with state and then have the MLP reduce it down to [128 x 1]
Pass in the state into the big MLP directly
History network:
- Looks at a window of recent past information
- Use RMA technique to try to adapt to hidden dynamics by looking at recent history
Big Block receives:
- Feature extractor output ([128 x 1])
- Observable state ([8 x 1])
- History/adaptation output ([8 x 1])
They are fused together and fed into a MLP with hidden layers: [100, 100]
Then it outputs: